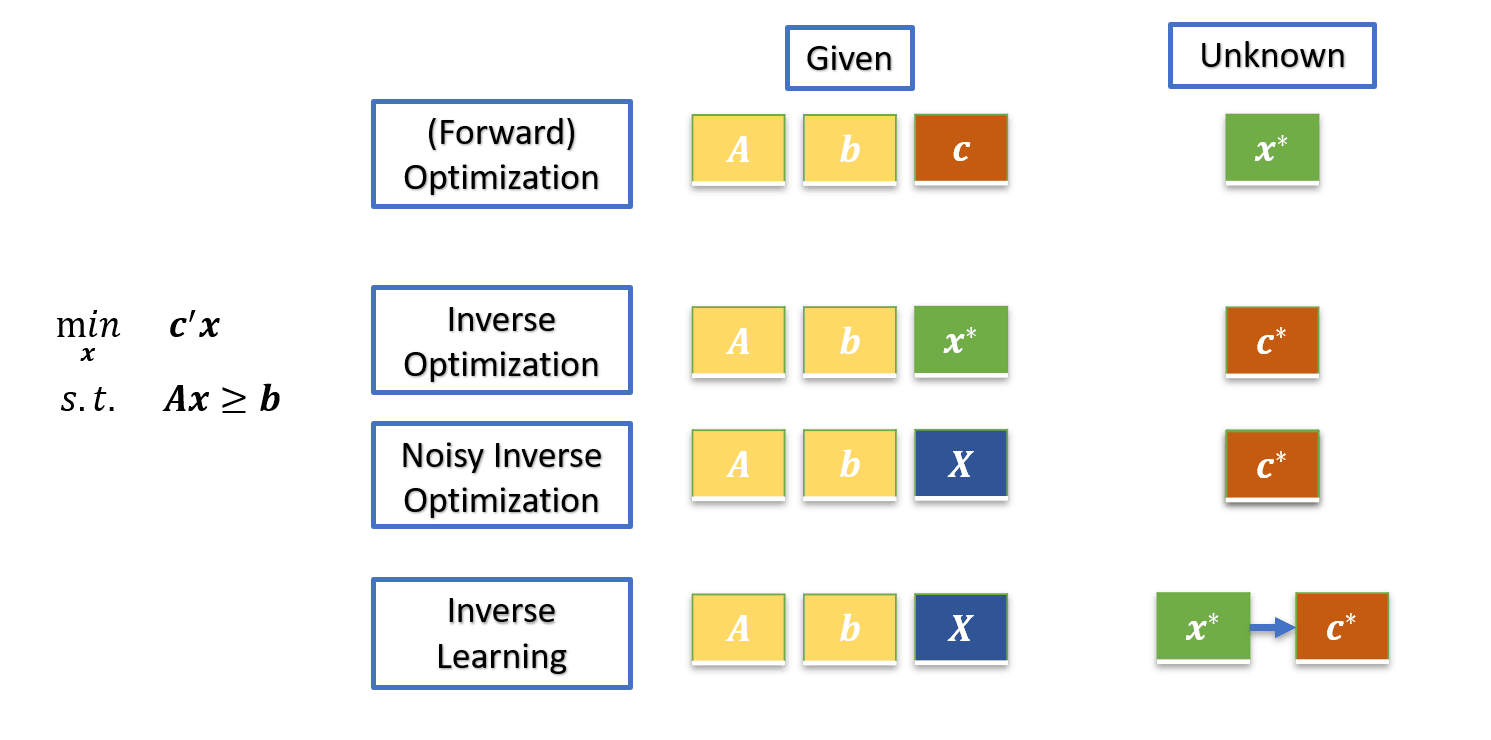
Many real decisions are shaped by an optimization problem that nobody has fully written down. The constraints may come from expert rules, safety limits, or clinical guidelines, while the objective reflects human preferences and trade-offs that you only see indirectly through behavior. This body of work treats observed decisions as noisy, imperfect glimpses of an underlying "best" choice, and uses inverse optimization to learn both (i) a representative optimal decision that matches the data and (ii) the preference structure that makes that decision make sense under the known constraints. It also makes the method usable in settings like personalized nutrition and other healthcare decision-support problems by explicitly handling the tension between staying close to observed behavior and enforcing important expert constraints, and by offering structured ways to move along that spectrum when gradual change is the realistic goal.
A second thrust is making these learned models trustworthy when data are limited and noisy, which is exactly the regime most applications live in. Instead of only saying "the estimates converge eventually," the work builds probability-aware guarantees: finite-sample error bounds that link how much data you have, how confident you want to be, and how tight the resulting uncertainty radius is under sub-Gaussian noise, with optimization structure enforced through KKT conditions rather than ad hoc fitting. In parallel, it develops likelihood-based inference for inverse convex optimization, including confidence regions constructed in decision space and then mapped to the set of parameters that could support those decisions, which directly addresses the non-identifiability that often appears in inverse problems.
Publications
Inverse learning: Solving partially known models using inverse optimization
Ahmadi F, Ganjkhanloo F, Ghobadi K
arXiv preprint